toggle
Primary menu
- ...
- ISTQB Certification
- ISTQB Certified Tester - Foundation Level (CTFL)
- ISTQB Certified Tester Advanced Level - Agile Tester (CTAL-AT)
- ISTQB Certified Tester Advanced Level - Agile Technical Tester (CTAL-ATT)
- ISTQB Certified Tester Advanced Level - Technical Test Analyst (CTAL-TTA)
- ISTQB Certified Tester Advanced Level - Test Analyst (CTAL-TA)
- ISTQB Certified Tester Advanced Level - Test Management (CTAL-TM)
- ISTQB Certified Tester - Mobile Application Testing (CT-MAT)
- ISTQB Certified Tester - AI Testing (CT-AI)
- ISTQB Certified Tester - Model-Based Tester (CT-MBT)
- ISTQB Certified Tester - Testing with Generative AI (CT-GenAI)
- ISTQB Certified Tester Acceptance Testing (CT-AcT)
- ISTQB Certified Tester Advanced Level Test Automation Engineering (CTAL-TAE)
- ISTQB Certified Tester Agile Test Leadership at Scale (CT-ATLaS)
- ISTQB Certified Tester Automotive Software Tester (CT-AuT)
- ISTQB Certified Tester Gambling Industry Tester (CT-GT)
- ISTQB Certified Tester Game Testing (CT-GaMe)
- ISTQB Certified Tester Performance Testing (CT-PT)
- ISTQB Certified Tester Security Test Engineer (CT-STE)
- ISTQB Certified Tester Security Tester (CT-SEC)
- ISTQB Certified Tester Test Automation Strategy (CT-TAS)
- ISTQB Certified Tester Usability Testing (CT-UT)
- ASQ Certification
- ASQ Certified Six Sigma Black Belt (CSSBB)
- ASQ Certified Six Sigma Green Belt (CSSGB)
- ASQ Certified Six Sigma Yellow Belt (CSSYB)
- ASQ Certified Quality Improvement Associate (CQIA)
- ASQ Certified Quality Auditor (CQA)
- ASQ Certified Quality Engineer (CQE)
- ASQ Certified Manager of Quality/Organizational Excellence (CMQ/OE)
- ASQ Certified Software Quality Engineer (CSQE)
- ASQ Certified Reliability Engineer (CRE)
- ASQ Certified Quality Inspector (CQI)
- ASQ Certified Quality Technician (CQT)
- ASQ Certified Calibration Technician (CCT)
- ASQ Certified Construction Quality Manager (CCQM)
- ASQ Certified Food Safety and Quality Auditor (CFSQA)
- ASQ Certified Master Black Belt (CMBB)
- ASQ Certified Medical Device Auditor (CMDA)
- ASQ Certified Pharmaceutical GMP Professional (CPGP)
- ASQ Certified Quality Process Analyst (CQPA)
- ASQ Certified Supplier Quality Professional (CSQP)
- IASSC Certification
- SHRM Certification
- ServiceNow Certification
- ServiceNow Certified Application Developer (CAD)
- ServiceNow Certified System Administrator (CSA)
- ServiceNow Certified Implementation Specialist - Platform Analytics (CIS-PA)
- ServiceNow Certified Implementation Specialist - Software Asset Management (CIS-SAM)
- ServiceNow Certified Implementation Specialist - Event Management (CIS-EM)
- ServiceNow Certified Implementation Specialist - IT Service Management (CIS-ITSM)
- ServiceNow Certified Implementation Specialist - Discovery (CIS-DISCO)
- ServiceNow Certified Implementation Specialist - Human Resources (CIS-HR)
- ServiceNow Certified Implementation Specialist - Vulnerability Response (CIS-VR)
- ServiceNow Certified Implementation Specialist - Customer Service Management (CIS-CSM)
- ServiceNow Certified Implementation Specialist - Service Mapping (CIS-SM)
- ServiceNow Certified Implementation Specialist - Security Incident Response (CIS-SIR)
- ServiceNow Certified Implementation Specialist - Risk and Compliance (CIS-RC)
- ServiceNow Certified Implementation Specialist - Cloud Provisioning and Governance (CIS-CPG)
- ServiceNow Certified Implementation Specialist - Field Service Management (CIS-FSM)
- ServiceNow Certified Implementation Specialist - Hardware Asset Management (CIS-HAM)
- ServiceNow Certified Implementation Specialist - Service Provider (CIS-SP)
- ServiceNow Certified Implementation Specialist - Strategic Portfolio Management (CIS-SPM)
- ServiceNow Certified Implementation Specialist - Third-party Risk Management (CIS-TPRM)
- ServiceNow Certified Implementation Specialist – Data Foundations (CIS-DF)
- ServiceNow Certified Platform Owner Associate (CPOA)
- ServiceNow Certified Platform Owner Professional (CPOP)
- ServiceNow Micro-Certification - UI Builder (SMC-UIB)
- ServiceNow Micro-Certification Agentic AI Executive (SMC-AAE)
- ServiceNow Micro-Certification Automated Test Framework Essentials (SMC-ATFE)
- ServiceNow Micro-Certification Flow Designer (SMC-FD)
- ServiceNow Micro-Certification Integration Hub (SMC-IH)
- ServiceNow Micro-Certification Introduction to App Engine Studio (SMC-IAES)
- ServiceNow Micro-Certification Playbooks Advanced (SMC-PA)
- ServiceNow Micro-Certification Playbooks Essentials (SMC-PE)
- ServiceNow Micro-Certification Predictive Intelligence (SMC-PI)
- ServiceNow Micro-Certification Service Portal (SMC-SP)
- OMG Certification
- OMG Certified UML Professional 2 - Foundation
- OMG Certified Expert in BPM 2 - Fundamental
- OMG Certified UML Professional 2 (OCUP 2) - Intermediate
- OMG Certified UML Professional 2 (OCUP 2) - Advanced Level
- OMG Certified Business Architect
- OMG Certified Expert in BPM 2 - Intermediate
- OMG Certified UAF Model User
- OMG-Certified Expert in BPM 2 - Advanced
- OMG-Certified Systems Modeling Professional - Advanced
- OMG-Certified Systems Modeling Professional - Fundamental
- OMG-Certified Systems Modeling Professional - Intermediate
- OMG-Certified Systems Modeling Professional - Model User
- PeopleCert Certification
- Scrum.org Certification
- Professional Scrum Master I (PSM I)
- Professional Scrum Master II (PSM II)
- Professional Scrum Product Owner I (PSPO I)
- Professional Scrum Product Owner II (PSPO II)
- Professional Scrum Developer (PSD I)
- Professional Agile Leadership (PAL I)
- Professional Agile Leadership - Evidence Based Management (PAL-EBM)
- Scaled Professional Scrum (SPS)
- Professional Scrum with Kanban (PSK I)
- Professional Scrum with User Experience (PSU I)
- Professional Product Discovery and Validation (PPDV)
- Professional Scrum Facilitation Skills (PSF Skills)
- Professional Scrum Master III (PSM III)
- Professional Scrum Product Backlog Management Skills (PSPBM Skills)
- Professional Scrum Product Owner III (PSPO III)
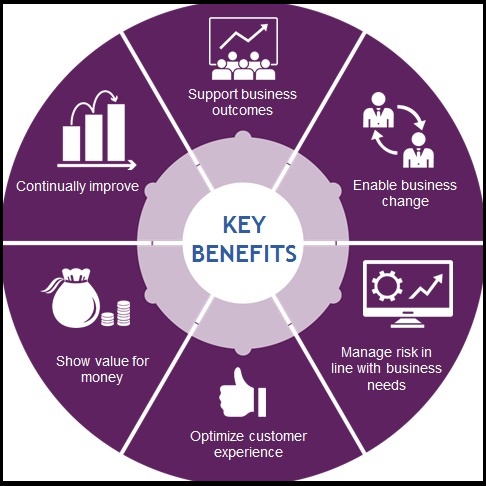
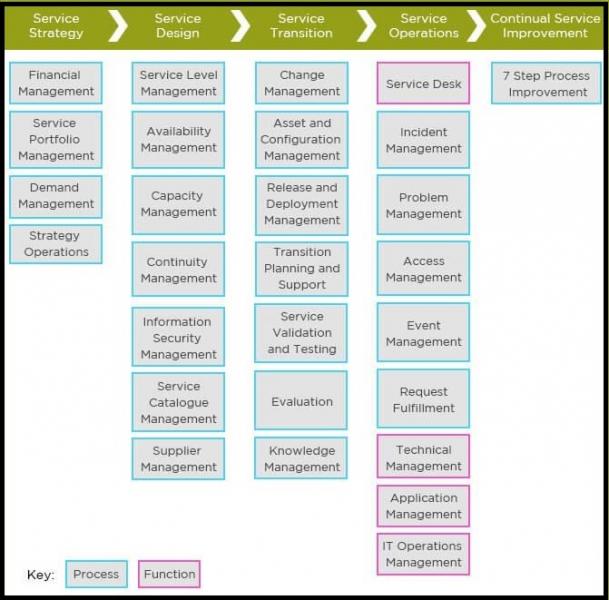
- ITIL Certification
- PRINCE2 Certification
- ASCM Certification
- LSSA Certification
- IIBA Certification
- IIBA Certified Business Analysis Professional (CBAP)
- IIBA Certification of Capability in Business Analysis (CCBA)
- IIBA Entry Certificate in Business Analysis (ECBA)
- IIBA Agile Analysis Certification (AAC)
- IIBA Certificate in Cybersecurity Analysis (CCA)
- IIBA Certificate in Product Ownership Analysis (CPOA)
- IIBA Certification in Business Data Analytics (CBDA)
- APMG International Certification
- APMG International Lean Six Sigma Black Belt
- APMG International Lean Six Sigma Green Belt
- APMG International Lean Six Sigma Yellow Belt - Foundation
- APMG International Change Management - Foundation
- APMG International Agile Project Management - Foundation (AgilePM Foundation)
- APMG International Agile Business Analysis Foundation (AgileBA Foundation)
- APMG International Agile Digital Services Foundation (AgileDS Foundation)
- APMG International Agile Programme Management - Foundation (AgilePgM Foundation)
- APMG International Data Literacy Fundamentals (DLFU)
- APMG International Enterprise Big Data Engineer (EBDE)
- APMG International Enterprise Big Data Professional (EBDP)
- APMG International Project Management for Sustainable Development Foundation (PM4SD Foundation)
- SAFe Certification
- Advanced SAFe Practice Consultant (ASPC)
- SAFe Advanced Scrum Master (SASM)
- SAFe Agile Product Management (APM)
- SAFe Agile Software Engineering (ASE)
- SAFe Agilist (SA)
- SAFe DevOps Practitioner (SDP)
- SAFe Government Practitioner (SGP)
- SAFe Lean Portfolio Management (LPM)
- SAFe Practitioner (SP)
- SAFe Product Owner/Product Manager (POPM)
- SAFe Program Consultant (SPC)
- SAFe Release Train Engineer (RTE)
- SAFe Scrum Master (SSM)
- SAFe for Architects (ARCH)
- APMP Certification
- APMP AI Micro-Certification (AI-M APMP)
- APMP Bid & Proposal Writing Micro-Certification (BW-M APMP)
- APMP Capture Practitioner-Level Certification (CAP APMP)
- APMP Executive Summaries Micro-Certification (ES-M APMP)
- APMP Foundation-Level Certification (CF APMP)
- APMP Graphics Micro-Certification (GR-M APMP)
- APMP Practitioner-Level Certification (CP APMP)
- DevOps Institute Certification
- Certified Agile Service Manager (CASM)
- Continuous Testing Foundation (CTF)
- DevOps Engineering Foundation (DOEF)
- DevOps Foundation (DOFD)
- DevOps Leader (DOL)
- DevSecOps Foundation (DSOF)
- DevSecOps Practitioner (DSOP)
- Observability Foundation (OBF)
- Site Reliability Engineering Foundation (SRE Foundation)
- Site Reliability Engineering Practitioner (SRE Practitioner)
- Value Stream Management Foundation (VSM Foundation)
- FINRA Certification
- FINRA Direct Participation Programs Representative Exam (Series 22)
- FINRA Investment Banking Representative Exam (Series 79)
- FINRA Investment Company and Variable Contracts Products Representative Exam (Series 6)
- FINRA Private Securities Offerings Representative Exam (Series 82)
- FINRA Securities Industry Essentials (SIE)
- FINRA Securities Trader Representative Exam (Series 57)
- GInI Certification
- GInI Authorized Growth Venture Assessor (AGVA)
- GInI Authorized Innovation Assessor (AInA)
- GInI Certified Chief Innovation Officer (CCInO)
- GInI Certified Design Thinking Professional (CDTP)
- GInI Certified Innovation Associate (CInA)
- GInI Certified Innovation Professional (CInP)
- GInI Certified Innovation Strategist (CInS)
- IAPM Certification
- IAPM Certified Agile Project Manager (CAPM)
- IAPM Certified International Project Manager (CIPM)
- IAPM Certified Junior Agile Project Manager (CJAPM)
- IAPM Certified Junior Project Manager (CJPM)
- IAPM Certified Project Manager (CPM)
- IAPM Certified Senior Agile Project Manager (CSAPM)
- IAPM Certified Senior Project Manager (CSPM)
- PRMIA Certification
- USGBC Certification
- USGBC LEED Accredited Professional Building Design and Construction (AP BD+C)
- USGBC LEED Accredited Professional Homes (AP Homes)
- USGBC LEED Accredited Professional Interior Design and Construction (AP ID+C)
- USGBC LEED Accredited Professional Neighborhood Development (AP ND)
- USGBC LEED Accredited Professional Operations and Maintenance (AP O+M)
- USGBC LEED Green Associate (GA)
- ISTQB Certification
- PMI Certification
- PMI Certified Associate in Project Management (CAPM)
- PMI Project Management Professional (PMP)
- PMI Professional in Business Analysis (PMI-PBA)
- PMI Program Management Professional (PgMP)
- PMI Portfolio Management Professional (PfMP)
- PMI Risk Management Professional (PMI-RMP)
- PMI Scheduling Professional (PMI-SP)
- PMI Agile Certified Practitioner (PMI-ACP)
- PMI Certified Professional in Managing AI (PMI-CPMAI)
- PMI Construction Professional (PMI-CP)
- PMI Green Project Manager - Basic (GPM-b)
- PMI Project Management Office Certified Professional (PMI-PMOCP)
- HRCI Certification
- Associate Professional in Human Resources (aPHR)
- Professional in Human Resources (PHR)
- Senior Professional in Human Resources (SPHR)
- Global Professional in Human Resources (GPHR)
- Associate Professional in Human Resources - International (aPHRi)
- Professional in Human Resources - California (PHRca)
- Professional in Human Resources - International (PHRi)
- Senior Professional in Human Resources - International (SPHRi)
- Open Group Certification
- The Open Group TOGAF 9 Part 1 (OG0-091)
- The Open Group TOGAF 9 Part 2 (OG0-092)
- The Open Group TOGAF 9 Combined Part 1 and Part 2 (OG0-093)
- The Open Group ArchiMate 3 Foundation (OGA-031)
- The Open Group ArchiMate 3 Practitioner (OGA-032)
- The Open Group Business Architecture Part 1 (OGB-001)
- The Open Group DPBoK Foundation Part 1 (OGD-001)
- The Open Group IT4IT 3 Foundation (OGIT-101)
- The Open Group IT4IT Part 1 Foundation (OG0-061)
- The Open Group Open Agile Architecture Practitioner (OGAA-001)
- The Open Group Open FAIR 2 Foundation (OGOF-101)
- The Open Group Open FAIR Part 1 (OG0-041)
- The Open Group TOGAF Business Architecture Foundation (OGBA-101)
- The Open Group TOGAF Enterprise Architecture Combined Part 1 and Part 2 (OGEA-103)
- The Open Group TOGAF Enterprise Architecture Part 1 (OGEA-101)
- The Open Group TOGAF Enterprise Architecture Part 2 (OGEA-102)
- The Open Group TOGAF Enterprise Architecture Practitioner Bridge (OGEA-10B)
- Pega Certification
- Certified Pega System Architect (CPSA)
- Certified Pega Senior System Architect (CPSSA)
- Certified Pega Robotics System Architect (CPRSA)
- Certified Pega Business Architect (CPBA)
- Certified Pega Decisioning Consultant (CPDC)
- Certified Pega Customer Service Developer (CPCSD)
- Certified Pega Data Scientist (CPDS)
- Certified Pega Lead System Architect (CPLSA)